Prof. Nathan Loewen specializes in the philosophy of religion and digital humanities among other things. This summer his research interests are taking him in a new direction at their intersection.
Last week, I travelled to the 2019 Humanities Intensive Learning and Teaching event to learn about text analysis from Katie Rawson. Here are just a few outcomes from those five days.
What to know about HILT and text analysis…
1. The Humanities Intensive Learning and Teaching is the best choice for U.S.-based academics who want to learn digital humanities in a focused, collaborative environment. My hunch is that HILT lines up competitively with the well-known DHSI at the University of Victoria and DHO at Oxford.

2. Driving to a meeting bests flying when intensive learning is the objective. On the drive from Tuscaloosa to Indianapolis, I was able to get through 16 of the 30 episodes of the Podcast: Machine Learning Guide. These are worth listening to several times.
3. There are some excellent blogs that explain the assumptions at work in digital humanities scholarship: Miriam Posner, Ted Underwood, and Ben Schmidt.
How to do text analysis…
4. When a research project involves a large number of entities or objects whose relations extend across dimensions such as time and space – a simple example may be review of journals for a topic or field – then digital analysis might be useful.
5. I need secure control of my data and scholarship (remember Flickr?). I am happy to learn that the more analytically powerful digital humanities tools are meant to live on my local computer. It’s up to me to maintain backups in any case!
What justifies adding text analysis to scholarship on religion…
6. There seem to be numerous intersections among critical theories, their methods, and the algorithms used for text analysis. To see what I mean, browse the table of contents contents of the annual Debates in the Digital Humanities.
7. I appreciate how digital humanities scholars fully agree that their data is a production of the “scholar’s study,” which is J.Z. Smith’s characterization of the ethereal location whenceforth comes an academic text: its topic, prose, analysis footnotes and citations (see the introduction to Imagining Religion, xi). The conventions of digital humanities do not eliminate this black box, but they do ask more from the proverbial “scholar’s study”: what choices were made about that data, the theoretical assumptions, methods, and practices? The best digital scholarship includes open explanations of how the digital scholar’s study dealt with aberations and outliers, modifications of algorithms and decisions, troubleshooting and most importantly: explanations of paths not taken.
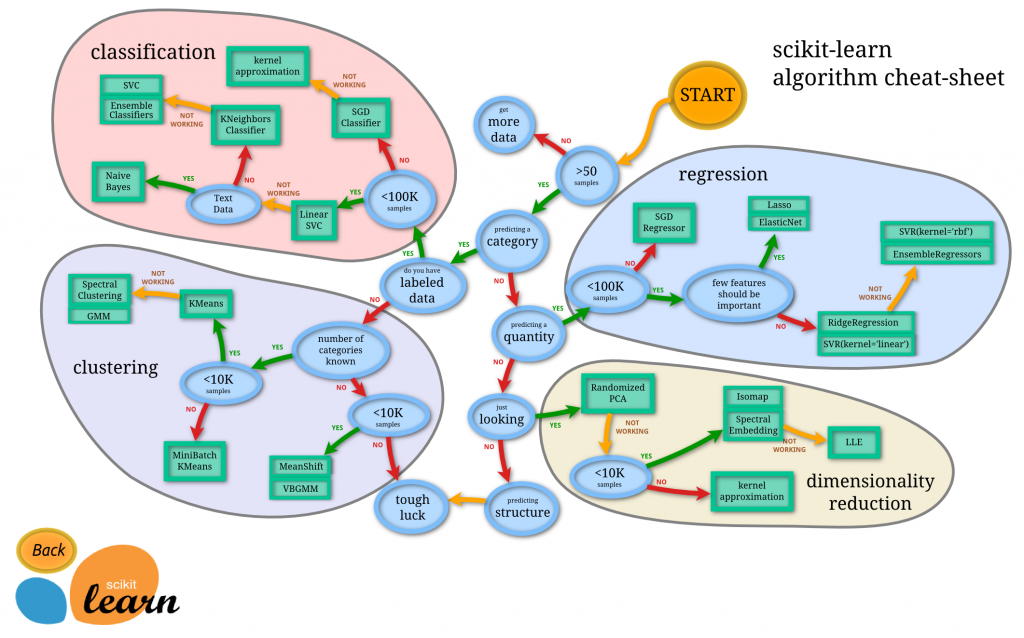
For example, the emphasis on explanation partly has to with do knowing which method to use with what data in the first place. Options abound, but outcomes are not guaranteed, as is shown in this cheatsheet from Scikit Learn or Jason Brownlee’s now-classic tour map of machine learning algorithms.